


Multimodal AI can be defined as machine learning models that have the capabilities to process and integrate data from numerous modalities or data types. Such modalities can involve images, text, video, audio, and other means of sensory input. Contrary to conventional AI models that are specialized in managing a single data type, multimodal AI combines and assesses distinct forms of data inputs to attain a more complete understanding and create more effective outputs.
For example, a multimodal can get an image of a landscape as an input and can provide a detailed summary describing the features of that place. Conversely, it can also receive a written description of the landscape and create an image based on that. The capabilities to operate across distinct modalities make AI more powerful.
Multimodal AI Vs Unimodal AI
When you compare multimodal AI to unimodal AI, the major difference exists in how they handle data. Unimodal AI only has the capability to work with only one type of data at a time, like text and images. These AI models are quite specialized but quite limited in terms of scope.
On the other hand, multimodal AI can process and incorporate numerous data types simultaneously, such as text, images, and sound. This capability enables them to understand more complicated scenarios and ensure more comprehensive, contextually aware, and rich responses.
| Multimodal | Unimodal |
| Multimodal AI can manage more than one data modality. | The unimodal is restricted to managing only a single type of data. |
| Offers rich and more contextually aware outputs | The interpretation of contexts and scope is quite limited. |
| It can create outputs in numerous formats. | It has certain restrictions and creates output in the same modality. |
Let us understand how multimodal works in detail in the next section-
Working of Multimodal AI
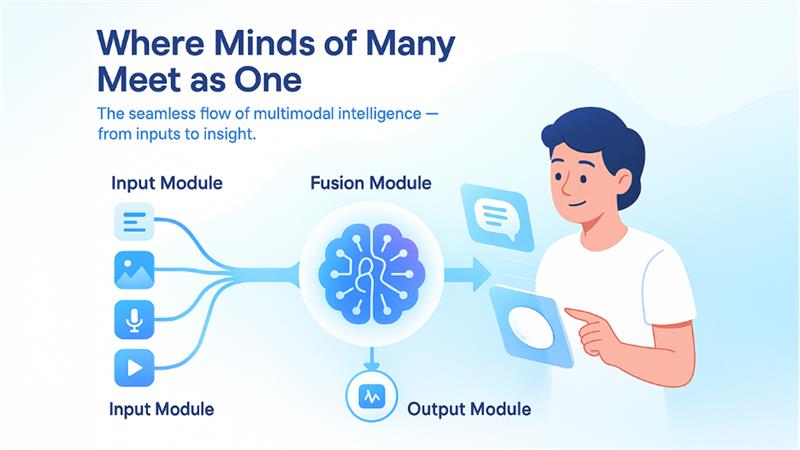
Essentially, a multimodal AI system contains only 3 components:
Input Module: The input model is composed of numerous unimodal neural networks. Every network manages a distinct type of data, and they collectively create the entire input module.
Fusion Module: Once the input model collects your data, the fusion model then becomes active. This model processes the data coming from an individual data type.
Output Module: This is the last component that delivers the main results.
Essentially, a multimodal AI platform utilizes numerous single-mode networks to manage distinct inputs, incorporate such inputs, and create outcomes as per the specifics of the incoming data. Multimodality can be expressed in diverse ways such as text-to-audio, text-to-image, audio-to-image, and all these integrated together. At their core, the operating principles in multimodal models are similar irrespective of specific modalities you consider.
How Open AI Popularized Multimodal AI?
Open AI has played an instrumental role in popularizing multimodal AI and facilitating the adoption of multimodal AI. When ChatGPT was first released by Open AI back in November 2022, it popularized the term generative AI. However, the initial versions were unimodal AI. It means that it was designed to understand only text inputs and generate only text outputs via Natural Language Processing. However, after the introduction of multimodal AI, generative AI became more powerful and valuable by enabling numerous types of inputs and outputs.
Open AI first introduced Dall-e, which was the company’s first multimodal implementation of GPT. However, what popularized the multimodal capabilities was GPT-4o. The release of GPT-4o introduced the world to the multimodal features of ChatGPT and changed the AI landscape completely.
What Are the Benefits of Multimodal AI?
The benefits of multimodal AI are several since it can perform flexible tasks when compared to unimodal AI. Key advantages of multimodal are explained in this section:
Improved Context: Multimodal AI can assess distinct inputs and identify different patterns. Thus, it leads to more human-like and natural outputs.
Accuracy: Since multimodal AI integrates distinct streams of data, it can offer more reliable and accurate results.
Improved Problem Solving: Since multimodal can process distinct inputs, it becomes much more capable of solving tricky challenges such as assessing multimedia context and or accurately diagnosing a medical condition.
Learning Across Domains: It can transfer modalities efficiently between distinct modalities, thereby improving adaptability of data to perform distinct tasks.
Creativity: In various domains such as art, content creation, and video creation, multimodal AI blends data and unlocks new possibilities to create advanced outputs.
Rich Interactions: Chatbots, augmented reality, and virtual assistants can leverage multimodal AI and ensure a more innovative user experience.
What Are Key Trends in Multimodal AI?
Mutimodal AI promises many more advancements and evolutions in the future, with numerous important trends shaping its application and development. The key trends are described as follows:
Unified Models:
GPT-V(ision) of Open AI, Google’s Gemini, and other centralized models are specialized in managing text, images, and other types of data within one architecture. Such models can interpret and create multimodal content quite smoothly.
Improved Cross-modal Interaction:
Applications in augmented reality and autonomous driving, for instance, need AI to process and incorporate data from distinct sensors such as LIDAR, camera, and more in real-time to make immediate decisions.
Multimodal Augmentation of Data:
Researchers are working on synthetic data that integrates numerous models (for instance, text descriptions with relevant images) to improve training datasets and enhance performance of the model.
Open-source and Collaboration:
Initiatives such as Google AI and Hugging Face are offering open-source AI tools, facilitating a collaborative environment for developers and researchers to advance the field.
What Are the Applications of Multimodal AI?
The possibility of utilizing multimodal AI in the current industrial landscape is endless. This section covers the common ways we can utilize multimodal AI:
Enhancing the Performance of Self-driving Cars by collecting and processing data from different sensors.
Developing New Tools for Medical Diagnosis that can process different types of data like health records, scan images, and genetic testing results.
Enhancing Chatbot and Virtual Assistant Experiences by processing a broad variety of inputs and creating more advanced outputs.
Implementing Enhanced Risk Assessment and Fraud Detection in banking finance, and other industries.
Assessing Data from Social Media includes images, text, and videos for enhanced moderation of content and trend detection.
Empowering Robots to More Effectively Understand and Interact with Their Environment, ensuring more human-level abilities and behavior.
What Are the Key Challenges of Multimodal AI?
There is no doubt that multimodal can solve a broad range of problems than unimodal platforms. However, just like any technology in its initial development stages, there are a few challenges that you need to be wary of:
Greater Data Needs:
Multimodal AI needs a copious volume of distinct data for it to be effectively trained. Collecting as well as labeling such data can be time-consuming and expensive.
Data Fusion:
Numerous modalities showcase distinct kinds and intensities of noise at different times, and there is no necessary temporal alignment. The variety in multimodal data can make the successful fusion of numerous models tricky.
Alignment:
Associated with data fusion, it is also quite tricky to align appropriate data representing the same space and time when distinct modalities (data types) are involved.
Translation:
Content translation across numerous modalities, either from one language to another or between different modalities, is a complex process known as multimodal translation. Giving an input to the AI system to generate an image based on text description is a primary example of this.
One of the most notable challenges in multimodal translation is ensuring that models can understand the semantic data and connections between audio, text, and images. It is also quite tricky to generate representations that capture multimodal data effectively.
Privacy and Ethical Concerns:
As it is true with all AI technology, there are numerous legitimate concerns centered around user privacy and ethics. People have biases and AI is created by people. So, naturally, AI models can also come up with certain biases such as discriminatory outputs against certain religion, race, sexuality, gender, etc. Furthermore, since AI relies on data for training, some data can include personal details of an individual. This can raise legit concerns regarding the names, numbers, addresses, financial details, etc.
Conclusion
In this blog, we have understood how the advent of multimodal AI has changed the landscape of AI. With more research and development, it will continue to improve AI capabilities. It promises a high-tech future with significant paradigm shifts in self-driving cars, healthcare, education, and creativity. However, we also need to consider its pressing challenges including privacy and ethical issues, large volume of data needs, and certain biases in outputs. As AI is evolving on a consistent basis, it is important to maximize its capabilities and deal with its challenges to accelerate AI’s widespread adoption.
Related Post:
Top Artificial Intelligence Models Transforming Industries
What Is an AI Model? From Basics to Brilliance in the AI Era
%201.png)

%201.png)

%201.png)

