


It takes more than occasional inspections and post-event troubleshooting to maintain dependable pipelines. Resilient systems are built on a foundation of continuous telemetry and well-tuned alerts, which give teams the real-time visibility and actionable signals they need to stop failures or identify them early. This article examines how to instrument pipelines, develop noise-reducing alerting strategies, and establish feedback loops that gradually increase reliability.
The Telemetry Foundation
Metrics, logs, and traces are the three telemetry pillars that support efficient pipeline monitoring. High-level indicators like throughput, error rates, latency percentiles, and queue depth are provided by metrics. Logs are essential for root cause analysis because they give specific events a thorough context. Traces reveal bottlenecks in end-to-end flows by connecting operations across services.
By consistently gathering all three, anomalies and their root causes can be correlated, transforming surface-level warnings into targeted corrective measures. To unify these signals and extract maximum value from them, teams should adopt a cohesive approach to schema, naming, and retention, so data stays query able and comparable over time. This holistic visibility is core to modern data observability practices.
Instrumentation best practices
To prevent performance regressions, the instrumentation should be lightweight and consistent. First, start by determining the crucial users, key pipeline stages, or what kind of business journeys each stage of the pipeline supports. CI/CD tools provide natural integration points for this instrumentation. Emit metrics for processing time, resource usage, and the number of successes and failures for each step. To enable targeted filtering during incidents, tag metrics with dimensions like environment, region, and pipeline versions. Because it enables automated tools to parse, aggregate, and connected logs to metrics and traces, structured logging with contextual fields is far better than free-form text.
When tracing, spread context across batch jobs and asynchronous boundaries to make sure observability throughout a request's complete lifecycle, including message queues and ETL transformations. Lastly, intelligently sample traces, while sampling successful fast paths, record all traces that are slow or incorrect.
Designing alerts that matter
Alerts ought to action-oriented signals that suggest a particular, recorded course of action. First, determine common failure modes such as persistently high error rates, throughput degradation, increased tail latency, or backpressure that results in message buildup with indicators that are measurable or quantifiable. Use rate-of-change, sustained thresholds, or anomaly detection in relation to historical baselines rather than sending alerts on individual anomalous datapoints.
When it is necessary, combine several signals into composite alerts (e.g., queue growth plus consumer lag plus decreased processing throughput) to provide teams with fewer and more reliable notifications. Assign alerts to the proper on-call rotation or runbook and implement severity levels and escalation procedures that take into account the impact on the business. Lastly, implement a routine review procedure that modifies thresholds in response to changing traffic patterns and retires or de-duplicates noisy alerts.
Reducing noise and alert fatigue
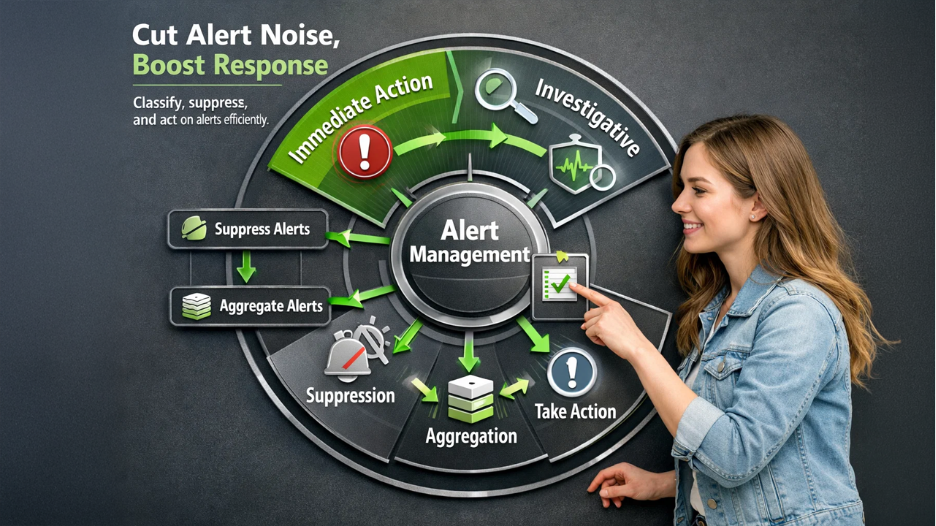
Because alert fatigues make responders ignore or take longer to respond to real incidents, it compromises reliability. To reduce noise, you can categorize alerts into three different groups: first that requires immediate action, second that should be investigated during business hours and lastly, informational. The scope of immediate alerts should be limited, and they should only be used in serious situations such as loss of data or unavailable services.
Degradations that are less serious can be linked to investigative alerts where patterns should be observed before it becomes worse. Instead of being assigned to on-call channels, informational alerts should be combined into daily summaries or dashboards that can provide meaningful insights on the situation. To avoid flooding during cascading failures, utilize suppression windows, auto-aggregation of similar alerts, and smart deduplication by correlation ID or pipeline component. To prevent repeatedly false positives, empower teams to swiftly mute noisy signals and inform the causes of mutations back to alert governance.
Automating response and remediation
By automating response and process of providing remedies can significantly speed up the recovery while freeing up on-call engineers so that they can focus on more complex decisions that require human expertise. For issues that are predictable, implement automated remediation playbooks that can scale capacity, restart failing workers, or reroute traffic temporarily.
By default, these runbooks should be safe while including pre-checks and require explicit overrides for operations that are risky. In ambiguous circumstances, ensure you combine automated actions with clear human-in-the-loop checkpoints. Integrating telemetry systems with incident management tools can automatically attach context to incidents. It can provide details such as recent logs, relevant traces, and a timeline showing deviations in metrics. This will save time by allowing you to diagnose errors instantly and improve response time across teams.
Embedding learning and continuous improvement
Reliability is not a one-time thing; rather, it is an ongoing process. Whenever an incident occurs, ensure to conduct a post-incident review that carefully captures all details about what happened, reasons why telemetry did or did not surface, and what are the next corrective steps to tackle this. To ensure that there are no visibility gaps, keep monitoring rules and dashboards updated and scale from relying on humans to automated runbooks where it's possible.
Track service-level objectives and error budgets to prioritize engineering work between feature development and reliability improvements. Use periodic chaos exercises or fault injection to validate observability and alerting designs, which reveals hidden dependencies, and ensures that alerts trigger meaningful responses during stressful situations.
Measuring success and maturity
You can measure improvements by tracking the average time to detect and acknowledge issues, as well as the average time to resolve them. Keep an eye on the rate of alert suppression and the percentage of alerts that lead to meaningful actions. These metrics show the quality of the signals. Assess business results, like downtime affecting customers or data quality problems, to confirm that your telemetry investments lower risk. Over time, mature organizations shift from reacting to alerts to using predictive signals that spot declining trends before they reach critical limits.
Continuous telemetry and tuned alerting are ongoing capabilities that need governance, attention, and iteration. Teams can successfully keep the pipelines running smoothly by instrumenting them comprehensively, modifying alerts that prioritize actionability over volume, automating safe remediation, and combining learning into operations. That way, teams can respond effectively and quickly in case problems arise. This will result in a system that can detect errors faster while also preventing them from occurring in the first place.
%201.png)

%201.png)

%201.png)
