


Introduction
The human face is more than simply a face in the context of multimedia and communication; it's a dynamic canvas on which even the smallest gestures and expressions can express feelings, reveal hidden meanings, and build sympathetic relationships. The advent of talking faces created by AI provides a glimpse into a future in which technology enhances the complexity of interactions between humans and AI.
In a surprising development in artificial intelligence, Microsoft Research has stunned the digital world by releasing its latest creation, VASA-1. This AI model represents a huge advancement that could revolutionize digital interactions.
In this blog, we’ll explore Microsoft’s VASA-1 AI Model, Its features, working principle, Applications, pros and cons, etc.
What is VASA-1?
VASA stands for Visual Affective Skills Audio
The term VAS describes the capacity to recognize and comprehend emotions in visual stimuli. This entails deciphering body language, facial emotions, and other visual cues from photos and videos. VAS is an everyday tool used by humans for socialization, communication, understanding, and "reading" others.
However, VAS is a new term in the realm of artificial intelligence that describes a system's ability to create images that make viewers feel something. In the case of VASA-1, this entails giving virtual characters incredibly lifelike facial emotions.

Key Features Of Microsoft’s VASA-1
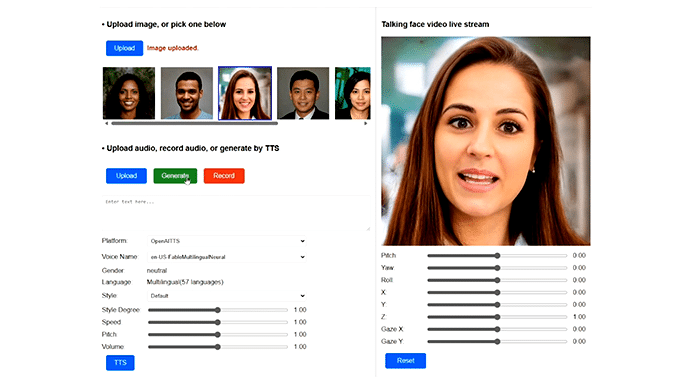
- Microsoft VASA-1 requires only one image and one audio file to produce incredibly lifelike videos.
- VASA-1 produces 512x512 video frames at 45 frames per second when processing data offline.
- When streaming online, it can support up to 40 frames per second with a delay of just 170 milliseconds beforehand.
- It opens the door to interactions with lifelike avatars that mimic human speech patterns in real-time.
Working Principle Of VASA-1
According to Microsoft, VASA-1 is setting the stage for the development of online artificial avatars in the future that can precisely replicate human conversational patterns.
Diffusion-based framework
The diffusion-based approach is a method of progressively enhancing an image's detail and decreasing its noise. By employing this method, the system begins with an indistinct image and refines it.
Head Movements and Expressions on the Face
VASA-1's holistic facial dynamics and head movement generation take into account all facial movements and head turns as a whole, producing a more cohesive and natural-looking appearance rather than concentrating on specific facial features (like lips or eyebrows).
LatentSpace
VASA-1 functions in a "face latent space," as researchers from Microsoft have explained. The substance of a face's "key data," such as its features, expressions, and head position, is captured by face latent space, a unique coded environment.
Application Of VASA-1 AI Model
Technology and Software Development:
Virtual communication platforms and human-computer interactions can be completely transformed by implementing advances in facial animation into software development.
Media and Entertainment:
By using AI-generated videos, the media and entertainment sector may increase viewer engagement and expedite the process of creating new content.
Education and Training:
The education sector can gain from AI capabilities by using virtual assistants and customizable NPCs to improve interactive learning experiences.
Pros
Enhanced realism in digital avatars, potentially improving user experience in virtual environments.
Innovative applications for teaching and amusement that enable the "revival" of historical personalities
New avenues for content generation in the creative industries without requiring large budgets or live performers.
Cons
Deepfakes in misinformation operations that have the potential to change public opinion or spark social upheaval pose a risk.
Actors and models may lose their professions as AI-generated images become more prevalent.
The use of someone else's likeness without that person's consent raises ethical, legal, and moral considerations. Stealing a person's image without their consent raises
Conclusion
Next-generation AI videos are unavoidable in the future. The advancement of artificial intelligence (AI) technology presents opportunities for businesses and industries such as education, healthcare, and accessibility. However, it will become more challenging to distinguish authentic online profiles from fraudulent ones.
In addition, there are significant privacy, compliance, and ethical issues with the training and application of these models. Big tech will keep releasing amazing but risky innovations as technology develops, leaving users and experts unsure of the potential consequences.
Read More - Artificial Intelligence: The Future API Testing
%201.png)

%201.png)

%201.png)

